Kubernetes on Microsoft Azure Kubernetes Service (AKS)#
You can create a Kubernetes cluster either through the Azure portal website, or using the Azure command line tools.
This page describes the commands required to setup a Kubernetes cluster using the command line. If you prefer to use the Azure portal see the Azure Kubernetes Service quickstart.
Prepare your Azure shell environment. You have two options, one is to use the Azure interactive shell, the other is to install the Azure command-line tools locally. Instructions for each are below.
Using the Azure interactive shell. The Azure Portal contains an interactive shell that you can use to communicate with your Kubernetes cluster. To access this shell, go to portal.azure.com and click on the button below.
Note
If you get errors like
could not retrieve token from local cache, try refreshing your browser window.The first time you do this, you’ll be asked to create a storage account where your shell filesystem will live.
Install command-line tools locally. You can access the Azure CLI via a package that you can install locally.
To do so, first follow the installation instructions in the Azure documentation. Then run the following command to connect your local CLI with your account:
az login
You’ll need to open a browser and follow the instructions in your terminal to log in.
Activate the correct subscription. Azure uses the concept of subscriptions to manage spending. You can get a list of subscriptions your account has access to by running:
az account list --refresh --output table
Pick the subscription you want to use for creating the cluster, and set that as your default. If you only have one subscription you can ignore this step.
az account set --subscription <YOUR-CHOSEN-SUBSCRIPTION-NAME>
Create a resource group. Azure uses the concept of resource groups to group related resources together. We need to create a resource group in a given data center location. We will create computational resources within this resource group.
az group create \ --name=<RESOURCE-GROUP-NAME> \ --location=centralus \ --output table
where:
--namespecifies the name of your resource group. We recommend using something that uniquely identifies this hub. For example, if you are creating a resource group for UC Berkeley’s 2018 Spring Data100 Course, you may give it a<RESOURCE-GROUP-NAME>ofucb_2018sp_data100_hub.--locationspecifies the location of the data center you want your resource to be in. In this case, we used thecentraluslocation. For other options, see the Azure list of locations that support AKS. Note that not all locations offer all VM sizes. To see a list of recommended locations, go to Azure Portal > Virtual Machines, click on “create..” and see the list of recommended locations in the drop down list forRegion.--output tablespecifies that the output should be in human readable format, rather than the default JSON output. We shall use this with most commands when executing them by hand.
Consider setting a cloud budget for your Azure account in order to make sure you don’t accidentally spend more than you wish to.
Choose a cluster name.
In the following steps we’ll run commands that ask you to input a cluster name. We recommend using something descriptive and short. We’ll refer to this as
<CLUSTER-NAME>for the remainder of this section.The next step will create a few files on your filesystem, so first create a folder in which these files will go. We recommend giving it the same name as your cluster:
mkdir <CLUSTER-NAME> cd <CLUSTER-NAME>
Create an ssh key to secure your cluster.
ssh-keygen -f ssh-key-<CLUSTER-NAME>
It will prompt you to add a password, which you can leave empty if you wish. This will create a public key named
ssh-key-<CLUSTER-NAME>.puband a private key namedssh-key-<CLUSTER-NAME>. Make sure both go into the folder we created earlier, and keep both of them safe!This command will also print out something to your terminal screen. You don’t need to do anything with this text.
Create a virtual network and sub-network.
Kubernetes does not by default come with a controller that enforces
networkpolicyresources.networkpolicyresources are important as they define how Kubernetes pods can securely communicate with one another and the outside sources, for example, the internet.To enable this in Azure, we must first create a Virtual Network with Azure’s own network policies enabled.
This section of the documentation is following the Microsoft Azure tutorial on creating an AKS cluster and enabling network policy, which includes information on using Calico network policies.
az network vnet create \ --resource-group <RESOURCE-GROUP-NAME> \ --name <VNET-NAME> \ --address-prefixes 10.0.0.0/8 \ --subnet-name <SUBNET-NAME> \ --subnet-prefix 10.240.0.0/16
where:
--resource-groupis the ResourceGroup you created--nameis the name you want to assign to your virtual network, for example,hub-vnet--address-prefixesare the IP address prefixes for your virtual network--subnet-nameis your desired name for your subnet, for example,hub-subnet--subnet-prefixesare the IP address prefixes in CIDR format for the subnet
We will now retrieve the application IDs of the VNet and subnet we just created and save them to bash variables.
VNET_ID=$(az network vnet show \ --resource-group <RESOURCE-GROUP-NAME> \ --name <VNET-NAME> \ --query id \ --output tsv) SUBNET_ID=$(az network vnet subnet show \ --resource-group <RESOURCE-GROUP-NAME> \ --vnet-name <VNET-NAME> \ --name <SUBNET-NAME> \ --query id \ --output tsv)
We will create an Azure Active Directory (Azure AD) service principal for use with the cluster, and assign the Contributor role for use with the VNet. Make sure
SERVICE-PRINCIPAL-NAMEis something recognisable, for example,binderhub-sp.SP_PASSWD=$(az ad sp create-for-rbac \ --name <SERVICE-PRINCIPAL-NAME> \ --role Contributor \ --scopes $VNET_ID \ --query password \ --output tsv) SP_ID=$(az ad app list \ --filter "displayname eq '<SERVICE-PRINCIPAL-NAME>'" \ --query [0].appId \ --output tsv)
You will need Owner role on your subscription for this step to succeed.
Create an AKS cluster.
At this stage, you may wish to think about customising your deployment. The Hub23 Deployment Guide contains instructions for deploying a Kubernetes cluster to Azure with autoscaling and multiple nodepools. These instructions can be combined so that all nodepools can autoscale.
The following command will request a Kubernetes cluster within the resource group that we created earlier.
az aks create \ --name <CLUSTER-NAME> \ --resource-group <RESOURCE-GROUP-NAME> \ --ssh-key-value ssh-key-<CLUSTER-NAME>.pub \ --node-count 3 \ --node-vm-size Standard_D2s_v3 \ --service-principal $SP_ID \ --client-secret $SP_PASSWD \ --dns-service-ip 10.0.0.10 \ --docker-bridge-address 172.17.0.1/16 \ --network-plugin azure \ --network-policy azure \ --service-cidr 10.0.0.0/16 \ --vnet-subnet-id $SUBNET_ID \ --output table
where:
--nameis the name you want to use to refer to your cluster--resource-groupis the ResourceGroup you created--ssh-key-valueis the ssh public key created--node-countis the number of nodes you want in your Kubernetes cluster--node-vm-sizeis the size of the nodes you want to use, which varies based on what you are using your cluster for and how much RAM/CPU each of your users need. There is a list of all possible node sizes for you to choose from, but not all might be available in your location. If you get an error whilst creating the cluster you can try changing either the region or the node size.--service-principalis the application ID of the service principal we created--client-secretis the password for the service principal we created--dns-service-ipis an IP address assigned to the Kubernetes DNS service--docker-bridge-addressis a specific IP address and netmask for the Docker bridge, using standard CIDR notation--network-pluginis the Kubernetes network plugin to use. In this example, we have used Azure’s own implementation.--network-policyis the Kubernetes network policy to use. In this example, we have used Azure’s own implementation.--service-cidris a CIDR notation IP range from which to assign service cluster IPsvnet-subnet-idis the application ID of the subnet we createdThis command will install the default version of Kubernetes. You can pass
--kubernetes-versionto install a different version.
This should take a few minutes and provide you with a working Kubernetes cluster!
Optionally, prepare autoscaling, where:
--vm-set-type VirtualMachineScaleSetsdeploys the cluster as a scale set.--enable-cluster-autoscalerenables autoscaling feature for your cluster--min-count 3is the minimum node count--max-count 6is the maximum node count
You can also enable autoscaling feature later, with:
SP_POOLNAME=$(az aks nodepool list \ --resource-group <RESOURCE-GROUP-NAME> \ --cluster-name <CLUSTER-NAME> \ --query [0].name \ --output tsv) az aks nodepool update \ --name $SP_POOLNAME \ --cluster-name <CLUSTER-NAME> \ --resource-group <RESOURCE-GROUP-NAME> \ --enable-cluster-autoscaler \ --min-count <DESIRED-MINIMUM-COUNT> \ --max-count <DESIRED-MAXIMUM-COUNT>
or update the parameters with
--update-cluster-autoscaler.az aks update \ --name <CLUSTER-NAME> \ --resource-group <RESOURCE-GROUP-NAME> \ --update-cluster-autoscaler \ --min-count <DESIRED-MINIMUM-COUNT> \ --max-count <DESIRED-MAXIMUM-COUNT> \ --output table
Both
--min-countand--max-countmust be defined.Read more about available options for the autoscaler here.
If you’re using the Azure CLI locally, install kubectl, a tool for accessing the Kubernetes API from the commandline:
az aks install-cli
Note: kubectl is already installed in Azure Cloud Shell.
Get credentials from Azure for
kubectlto work:az aks get-credentials \ --name <CLUSTER-NAME> \ --resource-group <RESOURCE-GROUP-NAME> \ --output table
where:
--nameis the name you gave your cluster--resource-groupis the ResourceGroup you created
This automatically updates your Kubernetes client configuration file.
Check if your cluster is fully functional
kubectl get node
The response should list three running nodes and their Kubernetes versions! Each node should have the status of
Ready, note that this may take a few moments.
Note
If you create the cluster using the Azure Portal you must enable RBAC. RBAC is enabled by default when using the command line tools.
Enabling Autoscaling (Optional)
If your cluster is prepared for autoscaling (
--enable-cluster-autoscaler), move to the Azure Portal to enable autoscaling and set rules to manage the Cluster Autoscaler.Navigate to your active subscription on the Portal.
Under “Resources”, select the VMSS. It should be named something like
aks-nodepool1-<random-str>-vmss.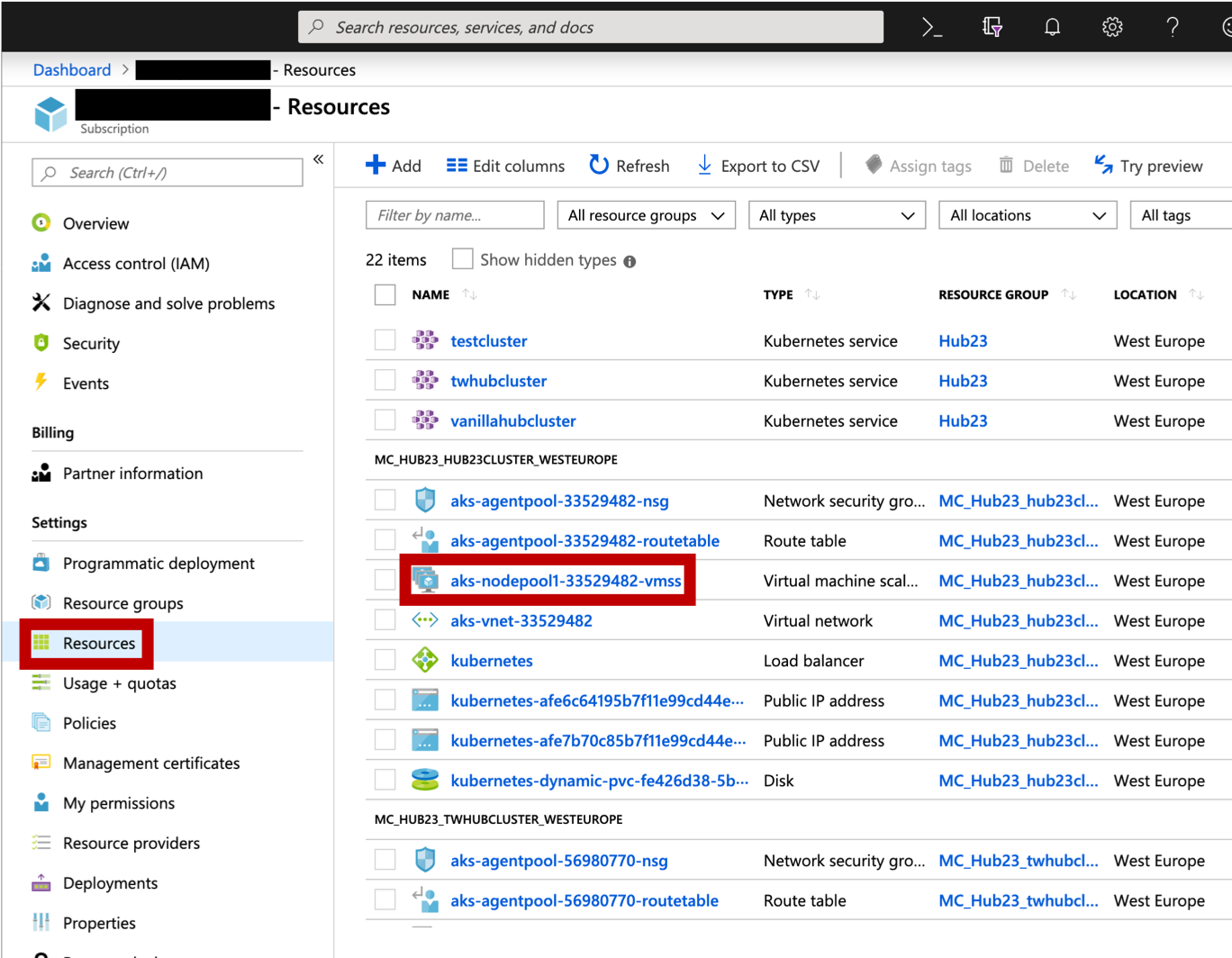
From the left-hand menu, select “Scaling”. Click the blue “Custom autoscale” button and an autogenerated form for a scale condition will appear. We will add two new rules to this condition:
Increase the instance count by 1 when the average CPU usage over 10 minutes is greater than 70%
Decrease the instance count by 1 when the average CPU usage over 10 minutes is less than 5%
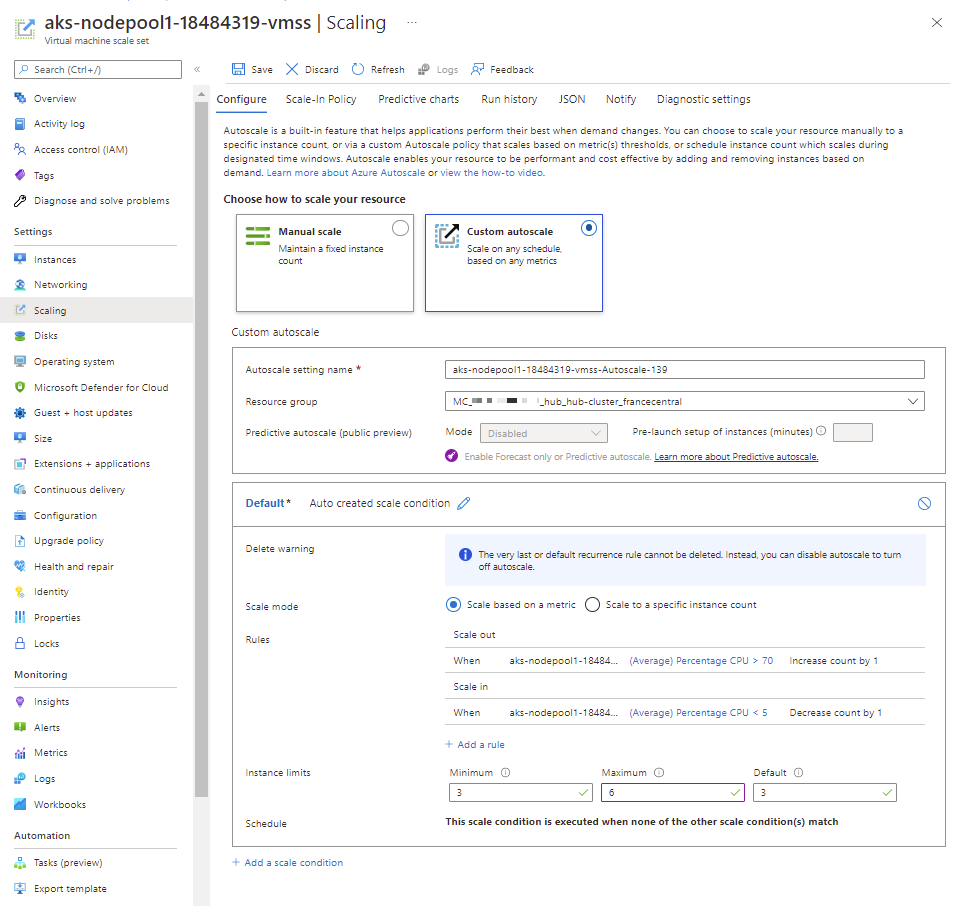
Make sure the “Scale based on metric” option is selected and click “+ Add new rule”, another autogenerated form will appear. This will be pre-filled with the required settings to fulfill our first rule, so save it by clicking “Update” and click “+ Add new rule” again.
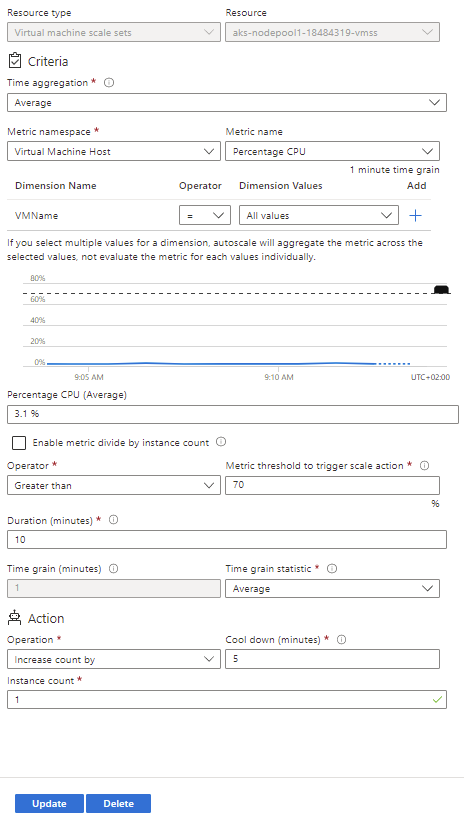
The second form needs to be edited for the second rule to decrease the instance count by 1 when the average CPU usage over 10 minutes is less than 5%. Save this rule and then save the overall scale condition, the cluster will be updated automatically.
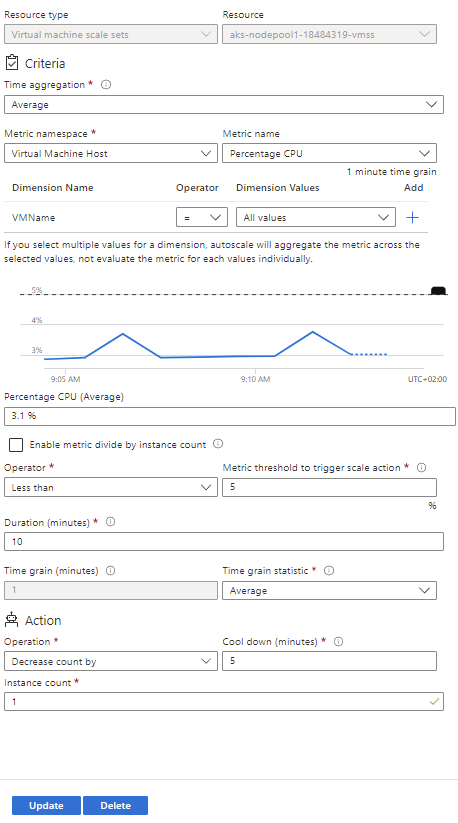
This form can also be used to change
--node-count/--min-count/--max-countthat was set previously by using the “Instance limits” section of the scale condition (“Default”, “Minimum” and “Maximum” respectively).
Congrats. Now that you have your Kubernetes cluster running, it’s time to begin Setting up helm.